


Unless someone you know printed this out for you to read and you’re holding a handful of 8.5” x 11” pages in your clammy little hands, there’s a pretty strong chance that you’re reading this article right now using an internet connection. That’s right: Your computer is sending and receiving nearly an unfathomable amount of information through the air and across miles of underground cables at approximately the speed of light. It’s cruising through the murky depths of the Atlantic Ocean, making pit stops at nondescript exchange points and cavernous data centers deep underground, picking up the information you need from whirring servers all across the globe just to deliver this website to your eyeballs. Wowzers!
Just because the internet is everywhere, however, doesn’t mean that it’s easily understood. In a way, this is by design—if things are confusing enough for the layperson, folks aren’t going to ask too many questions about why it all costs so much. After all, everyone needs the internet, right? We sign on the dotted line, thank our service providers for setting us up with paperless billing, and hope to God we’ll never have cause to call the customer service line and manually enter whatever a MAC address is. But learning what happens to our data when we send it out into the world is crucial knowledge that lends us some agency over our own online lives. This kind of technical internet literacy is one step towards gaining the upper hand on Messrs. Facebook, Whatsapp, and Instagram when they lose their own servers in the middle of Menlo Park, like they managed to do earlier this month.
In the interest of grounding our own relationship to the internet, here’s your lowdown on how the whole thing works, in the simplest terms possible.
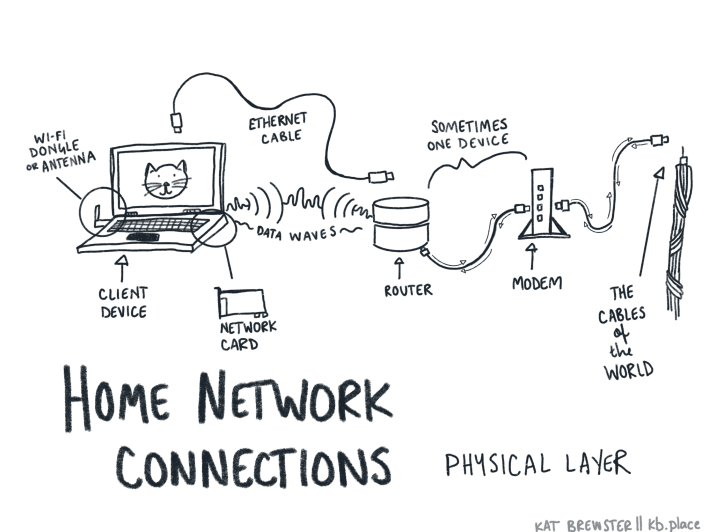
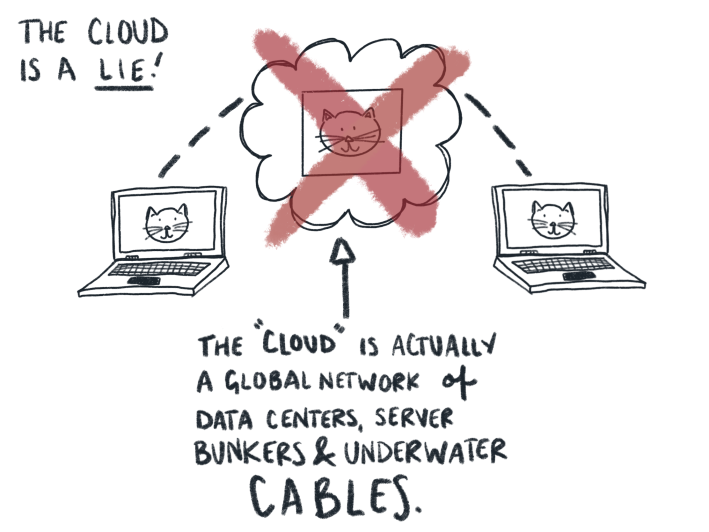
When you’re connecting the devices on your home network to the internet at large, you likely have a mixture of the following items: a computer with networking capabilities, a rat’s nest of ethernet cables, a modem, and a router. This home connection is pretty straightforward, and the easiest to imagine and describe in our day-to-day lives. Here’s what it seems like: A computer spits out data into wifi waves, and those wifi waves wiggle their way into your modem and router, which then somehow sends it traveling into someone else’s modem, router, and computer. So much of this seductive wifi-wiggle dance is invisible that it’s understandable to imagine that this process works the same way when scaled up to the global stage. Surely those wifi waves can just wiggle their little wifi-selves through the sky and into The Cloud and wiggle on down into their destination.
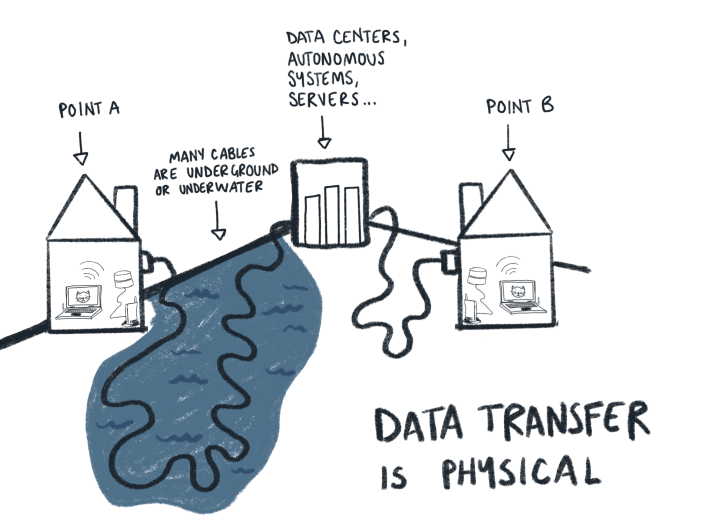
In reality, the only part of the internet that’s truly wireless is the end-device: a laptop, tablet, cell phone, or whatever. Every other part of the internet is tied down by real-world cables and ginormous data hubs in a kind of massive global circuit. It really is a series of tubes. In order to send your data around the world, or even right next door, it has to follow a series of steps.
Before your computer can even begin to spit out little wifi waves to your router and modem and into all those tubes, data has to get prepared to go out into the world. Be made tube-ready, if you will. To do so, data is broken down into bite-sized “packets,” each of which are given a whole host of information: its home address, its destination address, how many pieces it’s been broken down into, and how to put itself back together. Think of your data like a bachelorette party going out on the town: everyone is going to take separate cars, but they’ve all agreed to meet up at the same place at the same time and reassemble there. To prevent them from getting lost on the drive, they’ve each got the name of the bar and their own home address written on their arm in permanent marker. They look up the address of where they’re going in the phone book, and head out on the open road.
This road trip metaphor is already a pretty popular one (even if the bachelorette party angle might be new). It’s useful to speak of the “information superhighway” in terms of roads and cars, since it gets across so many parallels of networked communication: Geographic distance, the rules and standards by which we all agree to drive, how highways are graded, how well-trafficked a certain route is, the operation of exchanges, maps, junctions, and maintenance each have a rough parallel to how data travels online.
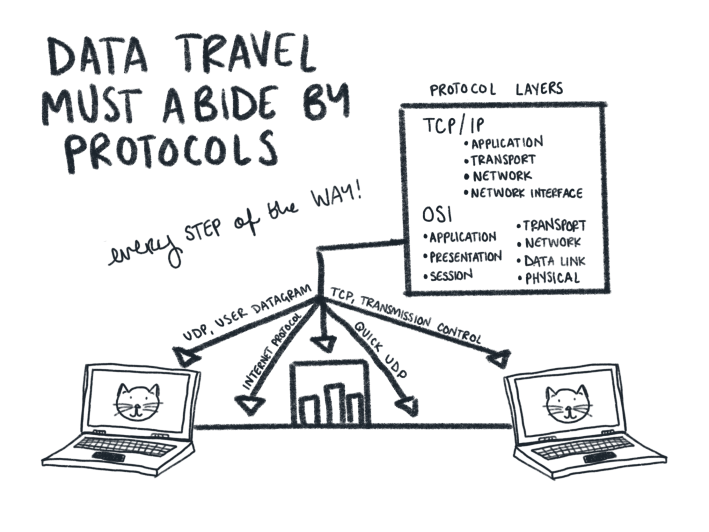
Take, for instance, the many rules for driving a car. We’ve got rules for getting a driver’s license, sure, but there are also rules which dictate how a city facilitates a population of people who drive everywhere. Roads have to be a certain width, there have to be certain numbers of parking spaces in certain locations to receive certain designations, there have to be the right kinds of street signs, the right kinds of access to interstates, and the right kinds of markers on the road to tell drivers which side of the road to drive on. Similarly, there are a lot of rules which dictate the technical components of data transfer when you’re cruising down the rainbow road of online life. You don’t have to worry too much about how these protocols set up and reinforce those technical standards (how does data get broken down into a packet?, for instance, or, how fast can data packets reassemble?), much in the same way that you don’t have to worry too much about how lane widths mutually reinforce the size of cars, or who decides where a stop sign should be. It can be helpful to know, though, that there is a whole whirring network of protocols which prop up and standardize these various layers of data transfer.
But let’s get back on the road.
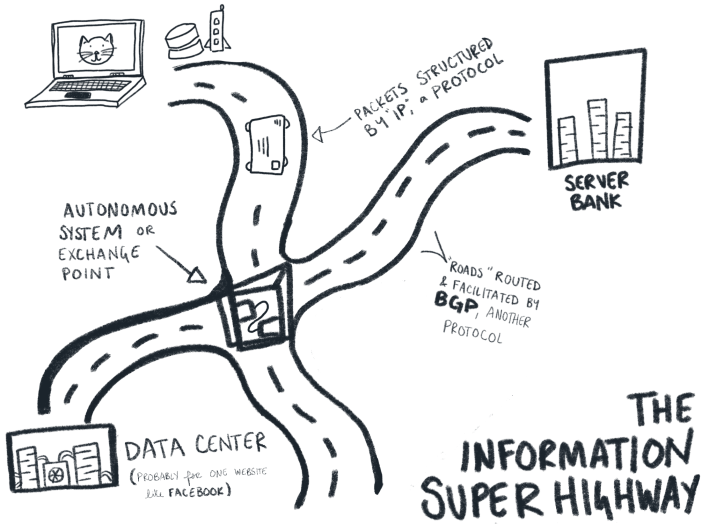
Out on the ‘net’s information superhighway, your data packets are entrusted with making their own individual decisions. They know where they’re going, in large part, due to the DNS—the Domain Name Service. When you type defector.com into your browser, for instance, your little data packets look up “defector.com” in the phone book to get a corresponding IP address. They head out in the direction of that address, which is held in a server. They know how to drive because they follow the right protocols (like TCP/IP), and they know they can use roads to get there because they’re using a map (another protocol, called BGP), and they get help along the way from various road signs and exchanges, called autonomous systems and internet exchange points. If all is well and good, packets arrive at their designated server and say, “Website please!”, put it in their trunk, and drive home to unload the web-readable page onto your screen using the very same methods that got them there in the first place.
Here’s what that might look like when we put all those pieces together, using google.com as the example:
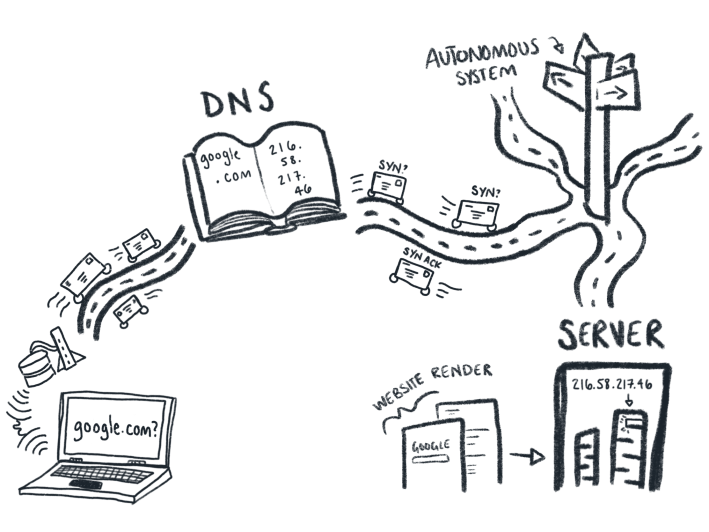
Since there are so many checkpoints for your data, it usually travels pretty smoothly. The flipside, of course, means that there are many points where things can go wrong. When a server is down, for instance, your data might be able to get all the way to a server, but without the right information to be able to render the website for you when it gets back. Or, perhaps you’ve encountered a “DNS lookup error,” where the fault is in the DNS servers which now can’t give your packets the address they need. Or your internet might get bogged down due to the sheer physical limitations of infrastructure and distance.
The fastest way to exchange data is almost always going to be a physical one, and any interference with those physical components is going to slow down the whole connection. Maybe you’re too far away from your router to maintain a strong wireless connection, or maybe you’re too far away from the physical exchange points across the globe which are meant to help route data to their destination. Internet options for people in rural areas, for instance, are much slimmer and slower than the options available for people in densely populated areas. Where someone in Los Angeles might have reliable access to nearly-fast-as-light fiber-optic cables, someone in a more rural area might be tethering to their phone. Location, location, location.
All of this can seem simple enough when information exchange is imagined from purely technical specifications. When the internet is devoid of politics, it only has to adhere to the laws and limitations of various protocols and cables to circulate a gif of a dancing baby in 4K HD. If left to its own devices, the internet is just a project that happens to work, held together by bubblegum and paperclips, constantly evolving and expanding. A dancing baby gif in beautiful 4K listens to the laws of no man.
As you can perhaps imagine, things start to get complicated as soon as you factor in the global scale, and the human cost of information exchange worldwide. The internet didn’t just show up one day—it’s a massively collaborative project, rooted in a history of U.S. military funding, RAND corporation contracts, and the kinds of pipe-smoking men who worked for the Department of Defense in the 1960s.
The standards and protocols of information exchange online were similarly decided by people or groups of people (not all of them pipe-smokers), and not without controversy. Adopting TCP/IP, for instance, as an agreed-upon standard for receiving and transmitting data wasn’t just the best way to transmit data—it was the standard that had the most institutional backing and government funds to implement. And if the idea of a group of dudes funded by the U.S. government (mostly the Department of Defense) making decisions about how the internet operates at its very core gives you the shivers, just wait until you hear about ICANN—the Internet Corporation for Assigned Names and Numbers.
Ostensibly, ICANN is a nonprofit network of selfless netizens who set up the phone book of the internet, the DNS. In practice, ICANN is a bizarre bureaucracy of tech-industry experts who periodically gather in a high-security L.A. basement to reaffirm their commitment to protecting the internet in a display of security theater reminiscent of a college fraternity initiation, or painfully boring Ocean’s Eleven heist. You might remember when they released a number of new domains—like the widely celebrated “.pizza,” or the controversial “.sucks”—opening the organization up to a whole host of trademark trouble and complaints. And that’s just one wing of hapless contemporary internet governance making millions of dollars off of a largely ignored slice of hidden infrastructure.
Things get similarly tricky when this awkward project of protocols and people propping up the internet is scaled up to the requirements of physical infrastructure at the global level. The internet has never been an abstract server floating in space to retrieve a dancing baby gif, but a real-life network of servers and data centers connected by a mess of underground and undersea cables owned by Facebook, Amazon, Google, and Microsoft (among other private industries). These undersea cables are laid through weeks-long sea voyages, operated in large part by private companies, to connect nearly all international internet traffic. And, of course, this global network has the capacity to reflect America’s own fears when we worry the Russians will physically cut our internet tubes if we lay them too close to the Kamchatkan coastline.
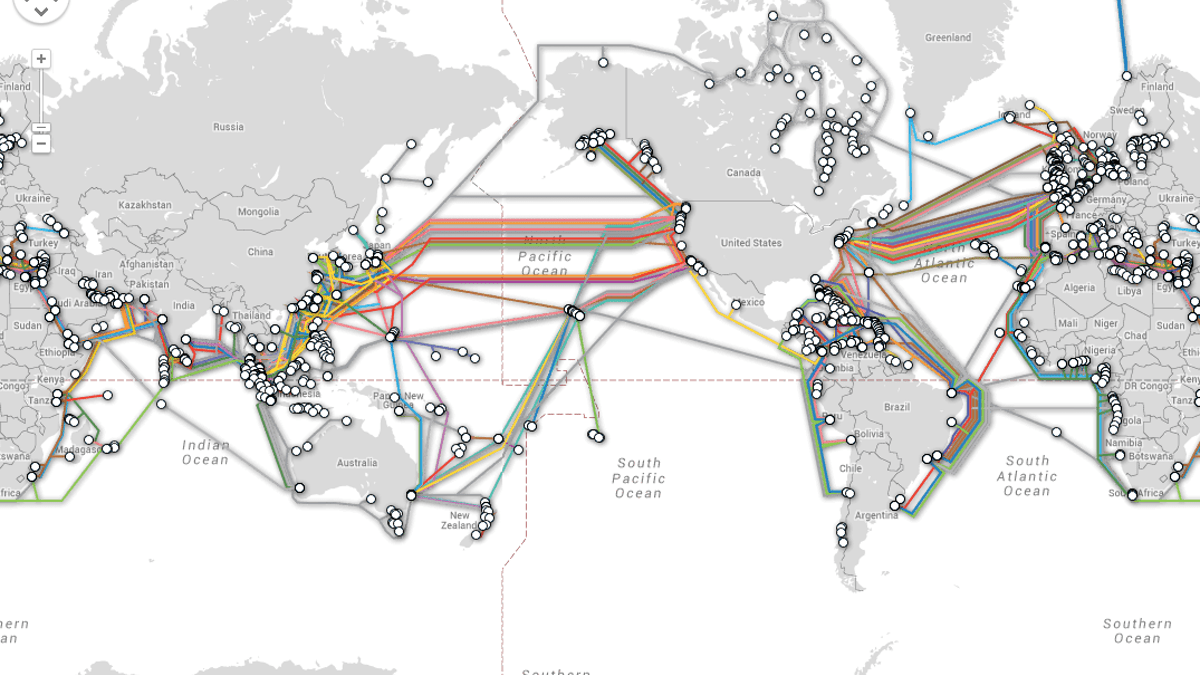
These private points of access often mean that reliable internet options are significantly limited in both the developing world and parts of the global south. It’s already difficult to get internet access to rural spots of a wealthy nation like the United States, but it gets even messier at the global scale: A U.N. report recently recognized that the majority of the world’s population lacks reliable internet access. In order to try and tend to this global need, Facebook’s team of do-gooder engineers helped to develop a program called “Free Basics.” Facebook bankrolled most of the service, which put cheap internet-connected devices into the hands of people who had otherwise limited access. These devices would strip down many parts of websites to their barest parts: heavy on the text, light on images. But not before the developers put Facebook front and center on devices, harvested mounds of user data, and neglected to provide enough device information in local languages. The program was met with a lot of backlash, with some likening it to “digital colonialism,” facilitating Facebook’s internet empire under the guise of a global good.
Already, a significant number of Facebook’s 3 billion users access the site from outside the United States. For many users, Facebook might as well be the internet. So, you can see why Facebook’s sudden outage at the beginning of October was a big deal. Facebook isn’t just a platform for estranged family members to post racist memes—it’s holding up a huge part of basic internet access worldwide.
In early October, engineers at Facebook tried to implement their own private BGP peering network (a fancy way of saying that they didn’t want to share the roads of their “information superhighway” with anyone else—and something they’ve been working on for a while). Needless to say, it backfired. Suddenly, data had no idea how to find Facebook’s servers. Not only that, but without an internal BGP roadmap to guide them to DNS, Facebook’s servers had no idea how to find Facebook’s servers. The knock-on effect inside of Facebook was significant: Everything from internal messaging systems to door badges weren’t functioning. As the VP of Infrastructure at Facebook put it, “the total loss of DNS broke many of the internal tools we’d normally use to investigate and resolve outages like this.” It was as if all the roads connecting Facebook’s data to itself and the world at large had vanished. Without any means of fixing the problem remotely, a small team of employees had to go to the Santa Clara offices to fix the problem by hand, undoing their configuration error.
Before Facebook, or even MySpace and Xanga and AOL, the internet was devised by teams of scientists and thinkers (and government military contractors) who dreamt of an intergalactic network of computers to catapult human development into the information age. People nowadays can use this awesome power to complain on Twitter.com about the gifs their bosses send them on Slack or to give their Postmates driver a five-star performance review so they don’t lose their job. It’s not exactly a utopia. But it is a necessity, and it’s worth fighting to make it the best version of itself. The ubiquity and mundanity of the internet belies its dramas, intricacies, and weaknesses—and if day-to-day internet users don’t start asking questions about how it works and why, Mark Zuckerberg is going to own it all one day.






